Parametric and Nonparametric Machine Learning Algorithms
What is a parametric machine learning algorithm and how is it different from a nonparametric machine learning algorithm?

In this post you will discover the difference between parametric and nonparametric machine learning algorithms.
Let’s get started.
Learning a Function
Machine learning can be summarized as learning a function (f) that maps input variables (X) to output variables (Y).
Y = f(x)
An algorithm learns this target mapping function from training data.
The form of the function is unknown, so our job as machine learning practitioners is to evaluate different machine learning algorithms and see which is better at approximating the underlying function.
Different algorithms make different assumptions or biases about the form of the function and how it can be learned.
Parametric Machine Learning Algorithms
Assumptions can greatly simplify the learning process, but can also limit what can be learned. Algorithms that simplify the function to a known form are called parametric machine learning algorithms.
Parametric machine learning algorithms make assumptions about the mapping function and have a fixed number of parameters. No matter how much data is used to learn the model, this will not change how many parameters the algorithm has. With a parametric algorithm, we are selecting the form of the function and then learning its coefficients using the training data.
The algorithms involve two steps:
- Select a form for the function.
- Learn the coefficients for the function from the training data.
An example of this would be the approach used in linear regression algorithms, where the simplified functional form can be something like:
B0+B1∗X1+B2∗X2=0
This assumption greatly simplifies the learning process; after selecting the initial function, the remaining problem is simply to estimate the coefficients B0, B1, and B2 using different samples of input variables X1 and X2.
Some more examples of parametric machine learning algorithms include:
- Logistic Regression
- Linear Discriminant Analysis
- Perceptron
- Naive Bayes
- Simple Neural Networks
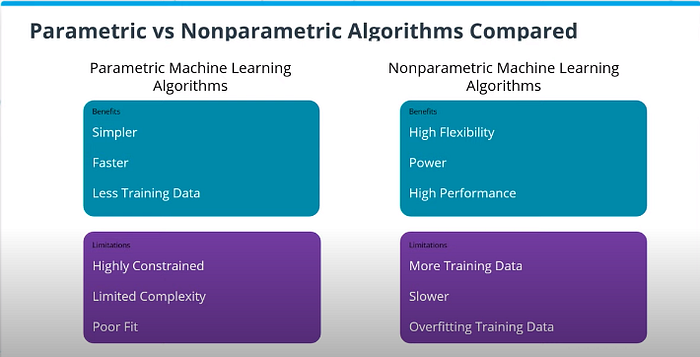
Benefits:
- Simpler and easier to understand; easier to interpret the results
- Faster when talking about learning from data
- Less training data required to learn the mapping function, working well even if the fit to data is not perfect
Limitations:
- Highly constrained to the specified form of the simplified function
- Limited complexity of the problems they are suitable for
- Poor fit in practice, unlikely to match the underlying mapping function.
Non-parametric Machine Learning Algorithms
Non-parametric algorithms do not make assumptions regarding the form of the mapping function between input data and output. Consequently, they are free to learn any functional form from the training data.
A simple example is the K-nearest neighbors (KNN) algorithm, KNN does not make any assumptions about the functional form, but instead uses the pattern that points have similar output when they are close.
Some more examples of popular nonparametric machine learning algorithms are:
- k-Nearest Neighbors
- Decision Trees like CART and C4.5
- Support Vector Machines
Benefits:
- High flexibility, in the sense that they are capable of fitting a large number of functional forms
- Power by making weak or no assumptions on the underlying function
- High performance in the prediction models that are produced
Limitations:
- More training data is required to estimate the mapping function
- Slower to train, generally having far more parameters to train
- Overfitting the training data is a risk; overfitting makes it harder to explain the resulting predictions
Summary
In this post you have discovered:
- The difference between parametric and nonparametric machine learning algorithms.
- Parametric methods make large assumptions about the mapping of the input variables to the output variable and in turn are faster to train, require less data but may not be as powerful.
- Nonparametric methods make few or no assumptions about the target function and in turn require a lot more data, are slower to train and have a higher model complexity but can result in more powerful models.
I hope this article will help you to better undrestand the subject.

References:
Microsoft Scholarship Foundation course Nanodegree Program : https://www.udacity.com/
